Graphing the Louvre
The Louvre digitized over 4,80,000 (!) works of art and made them available earlier this year through an Online Collections Database. And, I’ve been eyeing the Collection ever since, from wanting to piece it all together, in a Graph.
Having had help from my colleague Tom Geudens@Neo4j with the json extract (there is found to be no open access such as this one, at the time of this writing), I will walk you through steps on ingesting the same into Neo4j (ver. 4.3+).
Note : This post assumes you have a basic understanding of Neo4j and of what a Graph Database is, in general. The process of web-scraping is not within the scope of this blogpost. It also makes for a long post from being heavy on code ~ Cypher.
Each of the 4,80,000+ Exhibits at the Louvre is uniquely identifiable by an ARK ID and carries a uniform json structure that looks like this;

Now the json extract is organized as 1000 file system folders, each containing roughly 400+ json documents, making up all of the Louvre Collection in question. We start by ingesting most of the json structure (except for large text descriptive properties such as Bibliography, Exhibitions etc.) as Nodes labeled ‘Exhibit’, to be further labeled by Type at some point (viz. Paintings, Drawings & Prints, Sculptures, Furniture, Textiles, Jewellery & Finery, Writings & Inscriptions, Objects).
CREATE CONSTRAINT exhibitArkID ON (e:Exhibit) ASSERT e.arkID IS UNIQUE;CALL apoc.periodic.iterate(
"UNWIND range(0,999) AS item
WITH 'file:///Users/Priya_Jacob/Documents/neo4j43/neo4j-enterprise-4.3.0/import/louvre_collection_json/'+ apoc.text.lpad(toString(item),3,'0') AS f
RETURN f",
"CALL apoc.cypher.run('CALL apoc.load.directory(\"*.json\", $file, {recursive:false}) YIELD value AS url WITH \"file://\" + replace(url,\"\\\\\\\\\",\"/\") AS url CALL apoc.load.json(url) YIELD value RETURN value AS row',{file:f}) YIELD value
WITH value.row AS row
MERGE (e:Exhibit {arkID:trim(row.arkId)})
SET
e.collection = trim(row.collection),
e.category = CASE WHEN NOT row.index = [] THEN [x IN row.index.category | trim(x.value)] ELSE NULL END,
e.relatedWork = CASE WHEN NOT row.relatedWork = [] THEN [x IN row.relatedWork | SPLIT(x.objectUrl,'/')[-1]] ELSE NULL END,
e.modified = CASE WHEN NOT trim(row.modified) = '' THEN trim(row.modified) ELSE NULL END,
e.inventoryNumber = CASE WHEN NOT row.objectNumber = [] THEN [x IN row.objectNumber | trim(x.value)] ELSE NULL END,
e.description = CASE WHEN NOT trim(row.description) = '' THEN trim(row.description) ELSE NULL END,
e.dateOfDiscovery = CASE WHEN NOT trim(row.dateOfDiscovery) = '' THEN trim(row.dateOfDiscovery) ELSE NULL END,
e.title = CASE WHEN NOT trim(row.title) = '' THEN trim(row.title) ELSE NULL END,
e.objectType = CASE WHEN NOT trim(row.objectType) = '' THEN trim(row.objectType) ELSE NULL END,
e.placeOfCreation = CASE WHEN NOT trim(row.placeOfCreation) = '' THEN trim(row.placeOfCreation) ELSE NULL END,
e.provenance = CASE WHEN NOT trim(row.provenance) = '' THEN trim(row.provenance) ELSE NULL END,
e.heldBy = CASE WHEN NOT trim(row.heldBy) = '' THEN trim(row.heldBy) ELSE NULL END,
e.longTermLoanTo = CASE WHEN NOT trim(row.longTermLoanTo) = '' THEN trim(row.longTermLoanTo) ELSE NULL END,
e.namesAndTitles = CASE WHEN NOT trim(row.namesAndTitles) = '' THEN trim(row.namesAndTitles) ELSE NULL END,
e.denominationTitle = CASE WHEN NOT trim(row.denominationTitle) = '' THEN trim(row.denominationTitle) ELSE NULL END,
e.shape = CASE WHEN NOT trim(row.shape) = '' THEN trim(row.shape) ELSE NULL END,
e.titleComplement = CASE WHEN NOT trim(row.titleComplement) = '' THEN trim(row.titleComplement) ELSE NULL END,
e.inscriptions = CASE WHEN NOT trim(row.inscriptions) = '' THEN trim(row.inscriptions) ELSE NULL END,
e.placeOfDiscovery = CASE WHEN NOT trim(row.placeOfDiscovery) = '' THEN trim(row.placeOfDiscovery) ELSE NULL END,
e.technic = CASE WHEN NOT row.index = [] THEN [x IN row.index.technic | trim(x.value)] ELSE NULL END,
e.period = CASE WHEN NOT row.index = [] THEN [x IN row.index.period | trim(x.value)] ELSE NULL END,
e.material = CASE WHEN NOT row.index = [] THEN [x IN row.index.material | trim(x.value)] ELSE NULL END,
e.feature = CASE WHEN NOT row.index = [] THEN [x IN row.index.description | trim(x.value)] ELSE NULL END,
e.inscriptionType = CASE WHEN NOT row.index = [] THEN [x IN row.index.inscriptionType | trim(x.value)] ELSE NULL END,
e.place = CASE WHEN NOT row.index = [] THEN [x IN row.index.place | trim(x.value)] ELSE NULL END,
e.nameAndTitle = CASE WHEN NOT row.index = [] THEN [x IN row.index.nameAndTitle | trim(x.value)] ELSE NULL END,
e.denomination = CASE WHEN NOT row.index = [] THEN [x IN row.index.denomination | trim(x.value)] ELSE NULL END,
e.materialsAndTechniques = CASE WHEN NOT trim(row.materialsAndTechniques) = '' THEN trim(row.materialsAndTechniques) ELSE NULL END,
e.room = CASE WHEN NOT trim(row.room) = '' THEN trim(row.room) ELSE NULL END,
e.currentLocation = CASE WHEN NOT trim(row.currentLocation) = '' THEN trim(row.currentLocation) ELSE NULL END,
e.displayDateCreated = CASE WHEN NOT trim(row.displayDateCreated) = '' THEN trim(row.displayDateCreated) ELSE NULL END,
e.onomastics = CASE WHEN NOT trim(row.onomastics) = '' THEN trim(row.onomastics) ELSE NULL END
",
{batchSize:1, parallel:true}
)
We run a cursory check to see if the numbers tally with the 4,82,438 listings on the Louvre Collections page at this time of writing (since the site is a ‘work in progress’, from continuous repository update, as part of documentation efforts, by the Museum).
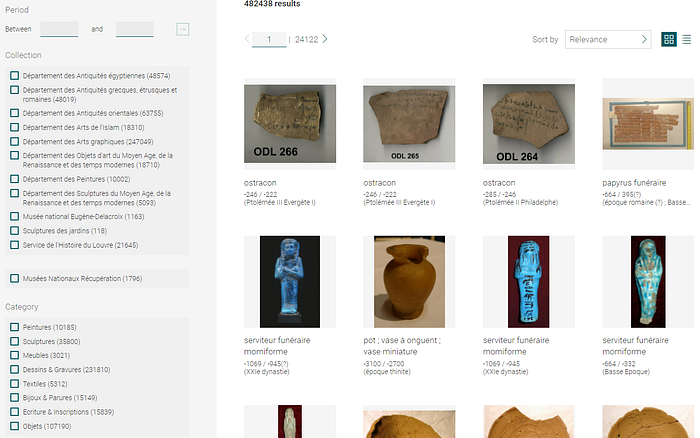
MATCH (n:Exhibit)
RETURN n.collection AS collection, COUNT(n) AS cnt
ORDER BY cnt DESCNext we bring in the Creators of each Exhibit, it being a list of maps with Artist Labels, Wikidata Identifiers, Linkages, Attributions & Origin (dates & places).

CALL apoc.periodic.iterate(
"UNWIND range(0,999) AS item
WITH 'file:///Users/Priya_Jacob/Documents/neo4j43/neo4j-enterprise-4.3.0/import/louvre_collection_json/'+ apoc.text.lpad(toString(item),3,'0') AS f
RETURN f",
"CALL apoc.cypher.run('CALL apoc.load.directory(\"*.json\", $file, {recursive:false}) YIELD value AS url WITH \"file://\" + replace(url,\"\\\\\\\\\",\"/\") AS url CALL apoc.load.json(url) YIELD value RETURN value AS row',{file:f}) YIELD value
WITH value.row AS row
MATCH (e:Exhibit {arkID:trim(row.arkId)})
WITH e, row AS row WHERE NOT row.creator = []
WITH e, row.creator AS l, range(0,size(row.creator)-1) AS nl
UNWIND nl AS n
WITH e,
COLLECT(CASE WHEN NOT l[n].label = '' THEN l[n].label ELSE '' END) AS labels,
COLLECT(CASE WHEN NOT l[n].wikidata = '' THEN l[n].wikidata ELSE '' END) AS wikidata,
COLLECT(CASE WHEN NOT l[n].linkType = '' THEN l[n].linkType ELSE '' END) AS linkTypes,
COLLECT(CASE WHEN NOT l[n].attributionLevel = '' THEN l[n].attributionLevel ELSE '' END) AS attributionLevels,COLLECT(CASE WHEN size([y IN [x IN CASE WHEN NOT l[n].dates = [] THEN range(0,size(l[n].dates)-1) ELSE [] END | CASE WHEN l[n].dates[x].type = 'date de naissance' THEN l[n].dates[x].date END] WHERE y IS NOT NULL|y])=0 THEN '' ELSE [y IN [x IN CASE WHEN NOT l[n].dates = [] THEN range(0,size(l[n].dates)-1) ELSE [] END | CASE WHEN l[n].dates[x].type = 'date de naissance' THEN l[n].dates[x].date END] WHERE y IS NOT NULL|y][0] END) AS dob,COLLECT(CASE WHEN size([y IN [x IN CASE WHEN NOT l[n].dates = [] THEN range(0,size(l[n].dates)-1) ELSE [] END | CASE WHEN l[n].dates[x].type = 'date de naissance' THEN l[n].dates[x].place END] WHERE y IS NOT NULL|y])=0 THEN '' ELSE [y IN [x IN CASE WHEN NOT l[n].dates = [] THEN range(0,size(l[n].dates)-1) ELSE [] END | CASE WHEN l[n].dates[x].type = 'date de naissance' THEN l[n].dates[x].place END] WHERE y IS NOT NULL|y][0] END) AS pob,COLLECT(CASE WHEN size([y IN [x IN CASE WHEN NOT l[n].dates = [] THEN range(0,size(l[n].dates)-1) ELSE [] END | CASE WHEN l[n].dates[x].type = 'date de mort' THEN l[n].dates[x].date END] WHERE y IS NOT NULL|y])=0 THEN '' ELSE [y IN [x IN CASE WHEN NOT l[n].dates = [] THEN range(0,size(l[n].dates)-1) ELSE [] END | CASE WHEN l[n].dates[x].type = 'date de mort' THEN l[n].dates[x].date END] WHERE y IS NOT NULL|y][0] END) AS dod,COLLECT(CASE WHEN size([y IN [x IN CASE WHEN NOT l[n].dates = [] THEN range(0,size(l[n].dates)-1) ELSE [] END | CASE WHEN l[n].dates[x].type = 'date de mort' THEN l[n].dates[x].place END] WHERE y IS NOT NULL|y])=0 THEN '' ELSE [y IN [x IN CASE WHEN NOT l[n].dates = [] THEN range(0,size(l[n].dates)-1) ELSE [] END | CASE WHEN l[n].dates[x].type = 'date de mort' THEN l[n].dates[x].place END] WHERE y IS NOT NULL|y][0] END) AS podSET e.creatorLabel = labels,
e.creatorWikiData = wikidata,
e.creatorLinkType = linkTypes,
e.creatorAttributionLevel = attributionLevels,
e.creatorDOB = dob,
e.creatorPOB = pob,
e.creatorDOD = dod,
e.creatorPOD = pod
",
{batchSize:1, parallel:true}
)
Now as it turns out, I don’t correspond in French, and therefore had a hard time comprehending what most of the unobvious literature meant, with no efficient way of translating the corpus at hand into English, the language of my choice. So, I resorted to looking up Wikidata for additional information, that would solve for some part of my problem. Now, I’d never worked with RDFs before and therefore found myself scrambling about wanting to query with SPARQL. I’ll provide references that helped me sail through at the end of this post. What you got to note is that Wikidata does not carry a reference to every Exhibit in the Louvre, so I had to make do with about 10K, which wasn’t still so bad, considering these would supposedly rank among popular vote or familiarity from having been documented by humans or machines in the first place.
SELECT (COUNT(DISTINCT ?ark) AS ?cnt)
WHERE {
?item wdt:P9394 ?ark .
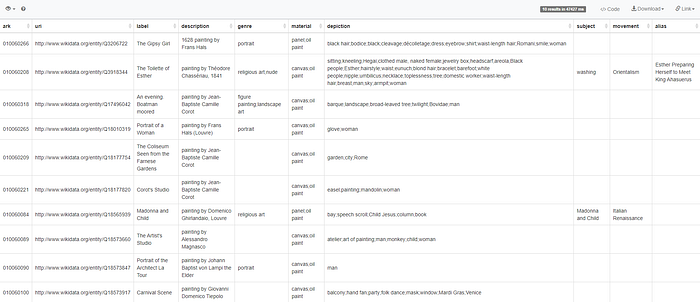
}I started out by writing this query, but not knowing all the tricks in the SPARQL bag, I had to break it down to keep it from timing out. So essentially, I’m trying to read additional information (in language English), on an Exhibit, such as the Label, its Description, Aliases, its Genre, its Materials, its Depictions, its Movement & Subject along with the Wikidata URI (you know, for posterity sake).
SELECT ?ark
(GROUP_CONCAT(DISTINCT(?item); separator = ";") AS ?uri)
(GROUP_CONCAT(DISTINCT(?itemLabel); separator = ";") AS ?label)
(GROUP_CONCAT(DISTINCT(?itemDescription); separator = ";") AS ?description)
(GROUP_CONCAT(DISTINCT(?itemGenreLabel); separator = ";") AS ?genre)
(GROUP_CONCAT(DISTINCT(?itemMaterialLabel); separator = ";") AS ?material)
(GROUP_CONCAT(DISTINCT(?itemDepictLabel); separator = ";") AS ?depiction)
(GROUP_CONCAT(DISTINCT(?itemSubjectLabel); separator = ";") AS ?subject)
(GROUP_CONCAT(DISTINCT(?itemMovementLabel); separator = ";") AS ?movement)
(GROUP_CONCAT(DISTINCT(?itemAltLabel); separator = ";") AS ?alias)
WHERE {
?item wdt:P9394 ?ark .
OPTIONAL {
?item rdfs:label ?itemLabel .
FILTER (lang(?itemLabel) = 'en') .
}
OPTIONAL {
?item schema:description ?itemDescription .
FILTER (lang(?itemDescription) = 'en') .
}
OPTIONAL {
?item wdt:P135 ?itemMovement .
?itemMovement rdfs:label ?itemMovementLabel .
FILTER (lang(?itemMovementLabel) = 'en') .
}
OPTIONAL {
?item wdt:P921 ?itemSubject .
?itemSubject rdfs:label ?itemSubjectLabel .
FILTER (lang(?itemSubjectLabel) = 'en') .
}
OPTIONAL {
?item wdt:P180 ?itemDepict .
?itemDepict rdfs:label ?itemDepictLabel .
FILTER (lang(?itemDepictLabel) = 'en') .
}
OPTIONAL {
?item wdt:P186 ?itemMaterial .
?itemMaterial rdfs:label ?itemMaterialLabel .
FILTER (lang(?itemMaterialLabel) = 'en') .
}
OPTIONAL {
?item wdt:P136 ?itemGenre .
?itemGenre rdfs:label ?itemGenreLabel .
FILTER (lang(?itemGenreLabel) = 'en') .
}
OPTIONAL {
?item skos:altLabel ?itemAltLabel .
FILTER (lang(?itemAltLabel) = 'en') .
}
}
GROUP BY ?arkA sample output (that did indeed run);
The above query was clearly inefficient because of which I had to query in short bursts to be able to update the ‘Exhibit’ Nodes.
//update wikiURI
CALL apoc.periodic.iterate(
'WITH
"SELECT ?ark
(GROUP_CONCAT(DISTINCT(?item); separator = \';\') AS ?uri)
WHERE {
?item wdt:P9394 ?ark .
}
GROUP BY ?ark" AS query
CALL apoc.load.jsonParams("http://query.wikidata.org/sparql?format=json&query=" + apoc.text.urlencode(query), {}, null)
YIELD value
RETURN value',
'WITH value.results.bindings AS arks
UNWIND arks AS ark
WITH \'cl\'+ark.ark.value AS ark, ark.uri.value AS uri
MATCH (e:Exhibit {arkID:ark})
SET e.wikiURI = uri',
{batchSize:100, parallel:true}
)//update wikiLabel
CALL apoc.periodic.iterate(
'WITH
"SELECT ?ark
(GROUP_CONCAT(DISTINCT(?itemLabel); separator = \';\') AS ?label)
WHERE {
?item wdt:P9394 ?ark .
?item rdfs:label ?itemLabel .
FILTER (lang(?itemLabel) = \'en\') .
}
GROUP BY ?ark" AS query
CALL apoc.load.jsonParams("http://query.wikidata.org/sparql?format=json&query=" + apoc.text.urlencode(query), {}, null)
YIELD value
RETURN value',
'WITH value.results.bindings AS arks
UNWIND arks AS ark
WITH \'cl\'+ark.ark.value AS ark, ark.label.value AS label
MATCH (e:Exhibit {arkID:ark})
SET e.wikiLabel = label',
{batchSize:100, parallel:true}
)//update wikiDescription
CALL apoc.periodic.iterate(
'WITH
"SELECT ?ark
(GROUP_CONCAT(DISTINCT(?itemDescription); separator = \';\') AS ?description)
WHERE {
?item wdt:P9394 ?ark .
?item schema:description ?itemDescription .
FILTER (lang(?itemDescription) = \'en\') .
}
GROUP BY ?ark" AS query
CALL apoc.load.jsonParams("http://query.wikidata.org/sparql?format=json&query=" + apoc.text.urlencode(query), {}, null)
YIELD value
RETURN value',
'WITH value.results.bindings AS arks
UNWIND arks AS ark
WITH \'cl\'+ark.ark.value AS ark, ark.description.value AS description
MATCH (e:Exhibit {arkID:ark})
SET e.wikiDescription = description',
{batchSize:100, parallel:true}
)//update wikiGenre
CALL apoc.periodic.iterate(
'WITH
"SELECT ?ark
(GROUP_CONCAT(DISTINCT(?itemGenreLabel); separator = \';\') AS ?genre)
WHERE {
?item wdt:P9394 ?ark .
?item wdt:P136 ?itemGenre .
?itemGenre rdfs:label ?itemGenreLabel .
FILTER (lang(?itemGenreLabel) = \'en\') .
}
GROUP BY ?ark" AS query
CALL apoc.load.jsonParams("http://query.wikidata.org/sparql?format=json&query=" + apoc.text.urlencode(query), {}, null)
YIELD value
RETURN value',
'WITH value.results.bindings AS arks
UNWIND arks AS ark
WITH \'cl\'+ark.ark.value AS ark, ark.genre.value AS genre
MATCH (e:Exhibit {arkID:ark})
SET e.wikiGenre = genre',
{batchSize:100, parallel:true}
)//update wikiMaterial
CALL apoc.periodic.iterate(
'WITH
"SELECT ?ark
(GROUP_CONCAT(DISTINCT(?itemMaterialLabel); separator = \';\') AS ?material)
WHERE {
?item wdt:P9394 ?ark .
?item wdt:P186 ?itemMaterial .
?itemMaterial rdfs:label ?itemMaterialLabel .
FILTER (lang(?itemMaterialLabel) = \'fr\') .
}
GROUP BY ?ark" AS query
CALL apoc.load.jsonParams("http://query.wikidata.org/sparql?format=json&query=" + apoc.text.urlencode(query), {}, null)
YIELD value
RETURN value',
'WITH value.results.bindings AS arks
UNWIND arks AS ark
WITH \'cl\'+ark.ark.value AS ark, ark.material.value AS material
MATCH (e:Exhibit {arkID:ark})
SET e.wikiMaterial = material',
{batchSize:100, parallel:true}
)//update wikiDepiction
CALL apoc.periodic.iterate(
'WITH
"SELECT ?ark
(GROUP_CONCAT(DISTINCT(?itemDepictLabel); separator = \';\') AS ?depiction)
WHERE {
?item wdt:P9394 ?ark .
?item wdt:P180 ?itemDepict .
?itemDepict rdfs:label ?itemDepictLabel .
FILTER (lang(?itemDepictLabel) = \'en\') .
}
GROUP BY ?ark" AS query
CALL apoc.load.jsonParams("http://query.wikidata.org/sparql?format=json&query=" + apoc.text.urlencode(query), {}, null)
YIELD value
RETURN value',
'WITH value.results.bindings AS arks
UNWIND arks AS ark
WITH \'cl\'+ark.ark.value AS ark, ark.depiction.value AS depiction
MATCH (e:Exhibit {arkID:ark})
SET e.wikiDepiction = depiction',
{batchSize:100, parallel:true}
)//update wikiSubject
CALL apoc.periodic.iterate(
'WITH
"SELECT ?ark
(GROUP_CONCAT(DISTINCT(?itemSubjectLabel); separator = \';\') AS ?subject)
WHERE {
?item wdt:P9394 ?ark .
?item wdt:P921 ?itemSubject .
?itemSubject rdfs:label ?itemSubjectLabel .
FILTER (lang(?itemSubjectLabel) = \'en\') .
}
GROUP BY ?ark" AS query
CALL apoc.load.jsonParams("http://query.wikidata.org/sparql?format=json&query=" + apoc.text.urlencode(query), {}, null)
YIELD value
RETURN value',
'WITH value.results.bindings AS arks
UNWIND arks AS ark
WITH \'cl\'+ark.ark.value AS ark, ark.subject.value AS subject
MATCH (e:Exhibit {arkID:ark})
SET e.wikiSubject = subject',
{batchSize:100, parallel:true}
)//update wikiMovement
CALL apoc.periodic.iterate(
'WITH
"SELECT ?ark
(GROUP_CONCAT(DISTINCT(?itemMovementLabel); separator = \';\') AS ?movement)
WHERE {
?item wdt:P9394 ?ark .
?item wdt:P135 ?itemMovement .
?itemMovement rdfs:label ?itemMovementLabel .
FILTER (lang(?itemMovementLabel) = \'en\') .
}
GROUP BY ?ark" AS query
CALL apoc.load.jsonParams("http://query.wikidata.org/sparql?format=json&query=" + apoc.text.urlencode(query), {}, null)
YIELD value
RETURN value',
'WITH value.results.bindings AS arks
UNWIND arks AS ark
WITH \'cl\'+ark.ark.value AS ark, ark.movement.value AS movement
MATCH (e:Exhibit {arkID:ark})
SET e.wikiMovement = movement',
{batchSize:100, parallel:true}
)//update wikiAlias
CALL apoc.periodic.iterate(
'WITH
"SELECT ?ark
(GROUP_CONCAT(DISTINCT(?itemAltLabel); separator = \';\') AS ?alias)
WHERE {
?item wdt:P9394 ?ark .
?item skos:altLabel ?itemAltLabel .
FILTER (lang(?itemAltLabel) = \'en\') .
}
GROUP BY ?ark" AS query
CALL apoc.load.jsonParams("http://query.wikidata.org/sparql?format=json&query=" + apoc.text.urlencode(query), {}, null)
YIELD value
RETURN value',
'WITH value.results.bindings AS arks
UNWIND arks AS ark
WITH \'cl\'+ark.ark.value AS ark, ark.alias.value AS alias
MATCH (e:Exhibit {arkID:ark})
SET e.wikiAlias = alias',
{batchSize:100, parallel:true}
)
A quick Property Data Profiling at this stage, after having brought in all desired Properties on the ‘Exhibit’ Nodes.
MATCH (n:Exhibit)
WITH n, KEYS(n) AS l
UNWIND l AS i
RETURN i, COUNT(n) AS cnt
ORDER BY cnt DESCNext, we’re ready to branch out further by expanding our Label footprint. We start off by defining our schema to ensure no Node duplication followed by creation of additional Nodes & Relationships.
CREATE CONSTRAINT collection ON (c:Collection) ASSERT c.collection IS UNIQUE;
CREATE CONSTRAINT category ON (c:Category) ASSERT c.category IS UNIQUE;
CREATE CONSTRAINT objectType ON (o:ObjectType) ASSERT o.objectType IS UNIQUE;
CREATE CONSTRAINT shape ON (s:Shape) ASSERT s.shape IS UNIQUE;
CREATE CONSTRAINT provenance ON (p:Provenance) ASSERT p.provenance IS UNIQUE;
CREATE CONSTRAINT technique ON (t:Technique) ASSERT t.technique IS UNIQUE;
CREATE CONSTRAINT material ON (m:Material) ASSERT m.material IS UNIQUE;
CREATE CONSTRAINT feature ON (f:Feature) ASSERT f.feature IS UNIQUE;
CREATE CONSTRAINT inscriptionType ON (i:InscriptionType) ASSERT i.inscriptionType IS UNIQUE;
CREATE CONSTRAINT place ON (p:Place) ASSERT p.place IS UNIQUE;
CREATE CONSTRAINT period ON (p:Period) ASSERT p.period IS UNIQUE;
CREATE CONSTRAINT room ON (r:Room) ASSERT r.room IS UNIQUE;
CREATE CONSTRAINT genre ON (g:Genre) ASSERT g.genre IS UNIQUE;
CREATE CONSTRAINT element ON (d:Depiction) ASSERT d.element IS UNIQUE;
CREATE CONSTRAINT subject ON (s:Subject) ASSERT s.subject IS UNIQUE;
CREATE CONSTRAINT movement ON (m:Movement) ASSERT m.movement IS UNIQUE;CALL apoc.periodic.iterate(
"MATCH (e:Exhibit)
RETURN e",
"WITH eFOREACH ( x IN CASE WHEN e.collection IS NOT NULL THEN [1] ELSE [] END | MERGE (cn:Collection {collection:toUpper(trim(e.collection))}) MERGE (e)-[:COLLECTION]->(cn) )FOREACH ( x IN CASE WHEN e.category IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN e.category | MERGE (cy:Category {category:toUpper(trim(y))}) MERGE (e)-[:CATEGORY]->(cy) ) )FOREACH ( x IN CASE WHEN e.relatedWork IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN e.relatedWork | MERGE (oth:Exhibit {arkID:trim(y)}) MERGE (e)-[:ASSOCIATION]->(oth) ) )FOREACH ( x IN CASE WHEN e.objectType IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN SPLIT(e.objectType,';') | MERGE (oe:ObjectType {objectType:toUpper(trim(y))}) MERGE (e)-[:OBJECT_TYPE]->(oe) ) )FOREACH ( x IN CASE WHEN e.shape IS NOT NULL THEN [1] ELSE [] END | MERGE (se:Shape {shape:toUpper(trim(e.shape))}) MERGE (e)-[:SHAPE]->(se) )FOREACH ( x IN CASE WHEN e.provenance IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN SPLIT(e.provenance,';') | MERGE (pe:Provenance {provenance:toUpper(trim(y))}) MERGE (e)-[:PROVENANCE]->(pe) ) )FOREACH ( x IN CASE WHEN e.technic IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN e.technic | MERGE (te:Technique {technique:toUpper(trim(y))}) MERGE (e)-[:TECHNIQUE]->(te) ) )FOREACH ( x IN CASE WHEN e.material IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN e.material | MERGE (ml:Material {material:toUpper(trim(y))}) MERGE (e)-[:MATERIAL]->(ml) ) )FOREACH ( x IN CASE WHEN e.feature IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN e.feature | MERGE (fe:Feature {feature:toUpper(trim(y))}) MERGE (e)-[:FEATURE]->(fe) ) )FOREACH ( x IN CASE WHEN e.inscriptionType IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN e.inscriptionType | MERGE (ie:InscriptionType {inscriptionType:toUpper(trim(y))}) MERGE (e)-[:INSCRIPTION_TYPE]->(ie) ) )FOREACH ( x IN CASE WHEN e.place IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN e.place | MERGE (pe:Place {place:toUpper(trim(y))}) MERGE (e)-[:PLACE]->(pe) ) )FOREACH ( x IN CASE WHEN e.period IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN e.period | MERGE (pd:Period {period:toUpper(trim(y))}) MERGE (e)-[:PERIOD]->(pd) ) )FOREACH ( x IN CASE WHEN e.room IS NOT NULL THEN [1] ELSE [] END | MERGE (rm:Room {room:toUpper(trim(e.room))}) MERGE (e)-[:ROOM]->(rm) )FOREACH ( x IN CASE WHEN e.wikiGenre IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN SPLIT(e.wikiGenre,';') | MERGE (ge:Genre {genre:toUpper(trim(y))}) MERGE (e)-[:GENRE]->(ge) ) )FOREACH ( x IN CASE WHEN e.wikiMaterial IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN SPLIT(e.wikiMaterial,';') | MERGE (wml:Material {material:toUpper(trim(y))}) MERGE (e)-[:MATERIAL]->(wml) ) )FOREACH ( x IN CASE WHEN e.wikiDepiction IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN SPLIT(e.wikiDepiction,';') | MERGE (dn:Depiction {element:toUpper(trim(y))}) MERGE (e)-[:DEPICTION]->(dn) ) )FOREACH ( x IN CASE WHEN e.wikiSubject IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN SPLIT(e.wikiSubject,';') | MERGE (st:Subject {subject:toUpper(trim(y))}) MERGE (e)-[:SUBJECT]->(st) ) )FOREACH ( x IN CASE WHEN e.wikiMovement IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN SPLIT(e.wikiMovement,';') | MERGE (mt:Movement {movement:toUpper(trim(y))}) MERGE (e)-[:MOVEMENT]->(mt) ) )
",
{batchSize:1000, parallel:false}
)
Most Exhibits have a ‘Current Location’ attached to them, where whereabouts are known & documented. Now, that ‘Location’ could well be within the confines of the Louvre or at an Establishment away, within or outside the country. For each Exhibit in a ‘Room’ within the Louvre, or where the ‘Current Location’ is found to be in the Louvre, we tag it with ‘the Louvre’, for everything else, we retain its original ‘Current Location’ tagging.
//link location
CREATE CONSTRAINT location ON (l:Location) ASSERT l.location IS UNIQUE;CREATE INDEX exhibitRoom FOR (e:Exhibit) ON (e.room);
CREATE INDEX exhibitCurrentLocation FOR (e:Exhibit) ON (e.currentLocation);-- set the current location to Musée du Louvre where room present
MATCH (e:Exhibit)
WHERE e.room IS NOT NULL
MERGE (l:Location {location:toUpper('Musée du Louvre')})
MERGE (e)-[:LOCATION]->(l)-- set the current location to Musée du Louvre where room NULL and current location contains Musée du Louvre
MATCH (e:Exhibit)
WHERE e.room IS NULL AND e.currentLocation CONTAINS 'Musée du Louvre'
MERGE (l:Location {location:toUpper('Musée du Louvre')})
MERGE (e)-[:LOCATION]->(l)-- set current location to current location for everything else
CALL apoc.periodic.iterate(
"MATCH (e:Exhibit)
WHERE e.room IS NULL AND e.currentLocation IS NOT NULL AND NOT e.currentLocation CONTAINS 'Musée du Louvre'
RETURN e",
"MERGE (l:Location {location:toUpper(trim(e.currentLocation))})
MERGE (e)-[:LOCATION]->(l)",
{batchSize:1000, parallel:false})-- current location not known
MATCH (n:Exhibit)
WHERE size((n)-[:LOCATION]->()) = 0
RETURN COLLECT(DISTINCT n.currentLocation), COLLECT(DISTINCT n.heldBy), COLLECT(DISTINCT n.longTermLoanTo)
Next we identify the ‘Holding’ & ‘Leasing’ Authority per Exhibit, which is to suggest while an Exhibit may be in possession of the Louvre, it could well have been leased long term to another Establishment. The Collection is also reflective of Exhibits leased to the Louvre by other Establishments.
//link holding and leasing authority
CREATE CONSTRAINT authority ON (a:Authority) ASSERT a.authority IS UNIQUE;CREATE INDEX exhibitHeldBy FOR (e:Exhibit) ON (e.heldBy);
CREATE INDEX exhibitLongTermLoanTo FOR (e:Exhibit) ON (e.longTermLoanTo);-- set the authority to Musée du Louvre where longTermLoanTo/heldBy contains Musée du Louvre
CALL apoc.periodic.iterate(
"MATCH (e:Exhibit)
WHERE e.heldBy CONTAINS 'Musée du Louvre'
RETURN e",
"MERGE (a:Authority {authority:toUpper('Musée du Louvre')})
MERGE (e)-[:HOLDING]->(a)",
{batchSize:1000, parallel:false})CALL apoc.periodic.iterate(
"MATCH (e:Exhibit)
WHERE e.longTermLoanTo CONTAINS 'Musée du Louvre'
RETURN e",
"MERGE (a:Authority {authority:toUpper('Musée du Louvre')})
MERGE (e)-[:LEASE]->(a)",
{batchSize:1000, parallel:false})-- set the authority to longTermLoanTo/heldBy where longTermLoanTo/heldBy does not contain Musée du Louvre
CALL apoc.periodic.iterate(
"MATCH (e:Exhibit)
WHERE NOT e.heldBy CONTAINS 'Musée du Louvre'
RETURN e",
"MERGE (a:Authority {authority:toUpper(trim(e.heldBy))})
MERGE (e)-[:HOLDING]->(a)",
{batchSize:1000, parallel:false})CALL apoc.periodic.iterate(
"MATCH (e:Exhibit)
WHERE NOT e.longTermLoanTo CONTAINS 'Musée du Louvre'
RETURN e",
"MERGE (a:Authority {authority:toUpper(trim(e.longTermLoanTo))})
MERGE (e)-[:LEASE]->(a)",
{batchSize:1000, parallel:false})
Finally, we link the Creators to their works of art! Now this has largely been the most challenging part because there is no decent way to identify People among People and Places, both being interchangeably linked (school of/workshop of/circle, entourage of/copy of/genre of/period of/identified with/attributed to etc.) and attributed (current/original/ancient/inventory/other etc.) to their Creations, within the json structure.
A few illustrations;
[
{
"creatorRole": "",
"attributedYear": "",
"attributedBy": "",
"doubt": "",
"linkType": "École de",
"label": "Italie",
"authenticationType": "",
"attributionLevel": "Attribution actuelle",
"wikidata": ""
}
,
{
"creatorRole": "",
"attributedYear": "",
"attributedBy": "",
"doubt": "",
"linkType": "Attribué à",
"dates": [
{
"date": "1698",
"place": "Florence",
"type": "date de mort"
},
{
"date": "1611",
"place": "Florence",
"type": "date de naissance"
}
],
"label": "Pignoni, Simone",
"authenticationType": "",
"attributionLevel": "Attribution actuelle",
"wikidata": "Q963528"
}
,
{
"creatorRole": "",
"attributedYear": "",
"attributedBy": "",
"doubt": "",
"linkType": "",
"dates": [
{
"date": "1657",
"place": "Gênes",
"type": "date de mort"
},
{
"date": "1632",
"place": "Gênes",
"type": "date de naissance"
}
],
"label": "Biscaino, Bartolommeo",
"authenticationType": "",
"attributionLevel": "Ancienne Attribution",
"wikidata": "Q2886080"
}
]
[
{
"creatorRole": "",
"attributedYear": "",
"attributedBy": "",
"doubt": "",
"linkType": "École de",
"dates": [
{
"date": "1516",
"place": "Venise",
"type": "date de mort"
},
{
"date": "vers 1430/1435",
"place": "Venise",
"type": "date de naissance"
}
],
"label": "Bellini, Giovanni",
"authenticationType": "",
"attributionLevel": "Attribution actuelle",
"wikidata": "Q17169"
}
,
{
"creatorRole": "",
"attributedYear": "",
"attributedBy": "",
"doubt": "",
"linkType": "École de",
"label": "Italie",
"authenticationType": "",
"attributionLevel": "Attribution actuelle",
"wikidata": ""
}
,
{
"creatorRole": "",
"attributedYear": "",
"attributedBy": "",
"doubt": "",
"linkType": "",
"dates": [
{
"date": "1516",
"place": "Venise",
"type": "date de mort"
},
{
"date": "vers 1430/1435",
"place": "Venise",
"type": "date de naissance"
}
],
"label": "Bellini, Giovanni",
"authenticationType": "",
"attributionLevel": "Inventorié Comme",
"wikidata": "Q17169"
}
,
{
"creatorRole": "",
"attributedYear": "",
"attributedBy": "",
"doubt": "",
"linkType": "Attribué à",
"dates": [
{
"date": "1554",
"place": "Venise",
"type": "date de mort"
},
{
"date": "vers 1470",
"place": "Trévise",
"type": "date de naissance"
}
],
"label": "Bissolo, Francesco",
"authenticationType": "",
"attributionLevel": "Ancienne Attribution",
"wikidata": "Q2566320"
}
]
So, follow along. We start with the simple rules and gradually move towards the complex.
//link creators
CREATE CONSTRAINT artistName ON (a:Artist) ASSERT a.name IS UNIQUE;//map labels with a wiki entity reference
CALL apoc.periodic.iterate(
"MATCH (e:Exhibit) WHERE size([z IN e.creatorLabel WHERE NOT size(trim(z))=0]) > 0 RETURN e",
"WITH e FOREACH ( y IN [x IN range(0,size(e.creatorLabel)-1) WHERE NOT size(trim(e.creatorLabel[x])) = 0 AND NOT size(trim(e.creatorWikiData[x])) = 0|x] | MERGE (a:Artist {name:toUpper(trim(e.creatorLabel[y]))}) SET a.wikiID = trim(e.creatorWikiData[y]), a.dateOfBirth = CASE WHEN NOT trim(e.creatorDOB[y]) = '' THEN trim(e.creatorDOB[y]) ELSE a.dateOfBirth END, a.placeOfBirth = CASE WHEN NOT trim(e.creatorPOB[y]) = '' THEN trim(e.creatorPOB[y]) ELSE a.placeOfBirth END, a.dateOfDeath = CASE WHEN NOT trim(e.creatorDOD[y]) = '' THEN trim(e.creatorDOD[y]) ELSE a.dateOfDeath END, a.placeOfDeath = CASE WHEN NOT trim(e.creatorPOD[y]) = '' THEN trim(e.creatorPOD[y]) ELSE a.placeOfDeath END MERGE (e)-[:CREATOR]->(a) )",
{batchSize:1000, parallel:false}
)//map labels that are comma separated supposedly meant to signify names
CALL apoc.periodic.iterate(
"MATCH (e:Exhibit) WHERE size([z IN e.creatorLabel WHERE NOT size(trim(z))=0]) > 0 RETURN e",
"WITH e FOREACH ( y IN [x IN range(0,size(e.creatorLabel)-1) WHERE size(trim(e.creatorWikiData[x])) = 0 AND trim(e.creatorLabel[x]) CONTAINS ',' |x] | MERGE (a:Artist {name:toUpper(trim(e.creatorLabel[y]))}) SET a.dateOfBirth = CASE WHEN NOT trim(e.creatorDOB[y]) = '' THEN trim(e.creatorDOB[y]) ELSE a.dateOfBirth END, a.placeOfBirth = CASE WHEN NOT trim(e.creatorPOB[y]) = '' THEN trim(e.creatorPOB[y]) ELSE a.placeOfBirth END, a.dateOfDeath = CASE WHEN NOT trim(e.creatorDOD[y]) = '' THEN trim(e.creatorDOD[y]) ELSE a.dateOfDeath END, a.placeOfDeath = CASE WHEN NOT trim(e.creatorPOD[y]) = '' THEN trim(e.creatorPOD[y]) ELSE a.placeOfDeath END MERGE (e)-[:CREATOR]->(a) )",
{batchSize:1000, parallel:false}
)//from the rest, map below titles & generalizations to anonymous
ANONYME
maître/MAITRE
peintre/painter
potierCALL apoc.periodic.iterate(
"MATCH (e:Exhibit) WHERE size([z IN e.creatorLabel WHERE NOT size(trim(z))=0]) > 0 RETURN e",
"WITH e FOREACH ( y IN [x IN range(0,size(e.creatorLabel)-1) WHERE size(trim(e.creatorWikiData[x])) = 0 AND (toUpper(trim(e.creatorLabel[x])) CONTAINS 'ANONYME' OR toLower(trim(e.creatorLabel[x])) CONTAINS 'maître' OR toUpper(trim(e.creatorLabel[x])) CONTAINS 'MAITRE' OR toLower(trim(e.creatorLabel[x])) CONTAINS 'peintre' OR toLower(trim(e.creatorLabel[x])) CONTAINS 'painter' OR toLower(trim(e.creatorLabel[x])) CONTAINS 'potier')|x] | MERGE (a:Artist {name:'ANONYME'}) MERGE (e)-[:CREATOR]->(a) )",
{batchSize:1000, parallel:false}
)
Now we’re still tasked with identifying People from Places from what is left to be mapped. Yet once again, we resort to Wikidata, for a listing of Countries in language French, that we can then use to eliminate Places with, from our data. Not quite the puritan way to perform Entity Recognition, but one that will do the job for now.
//retain class/family/series/group/manufacturer/atelier
//eliminate countries (incl. "pay", French for country)//create countries
CREATE CONSTRAINT countryURI IF NOT EXISTS ON (c:Country) ASSERT (c.uri) IS UNIQUE;WITH
"SELECT ?country ?countryENLabel ?countryFRLabel WHERE {
?country wdt:P31 wd:Q6256 .
OPTIONAL {
?country rdfs:label ?countryENLabel .
FILTER (lang(?countryENLabel) = 'en') .
}
OPTIONAL {
?country rdfs:label ?countryFRLabel .
FILTER (lang(?countryFRLabel) = 'fr') .
}
}
ORDER BY ?countryENLabel" AS query
CALL apoc.load.jsonParams("http://query.wikidata.org/sparql?format=json&query=" + apoc.text.urlencode(query), {}, null)
YIELD value
WITH value.results.bindings AS countries
UNWIND countries AS country
WITH country.country.value AS uri, country.countryENLabel.value AS countryEN, country.countryFRLabel.value AS countryFR
MERGE (c:Country {uri:uri})
SET c.countryEN = countryEN,
c.countryFR = countryFR//eliminate places from attributions
CALL apoc.periodic.iterate(
"
MATCH (c:Country) WHERE c.countryFR IS NOT NULL
WITH COLLECT(toUpper(trim(c.countryFR))) AS l
MATCH (e:Exhibit) WHERE size([z IN e.creatorLabel WHERE NOT size(trim(z))=0]) > 0 AND size((e)-[:CREATOR]->()) = 0
RETURN l, e",
"
WITH l, e
FOREACH ( y IN [x IN range(0,size(e.creatorLabel)-1) WHERE (NOT trim(e.creatorLabel[x]) = '') AND (NOT toUpper(trim(e.creatorLabel[x])) CONTAINS 'PAY') AND (size([i IN l WHERE toUpper(trim(e.creatorLabel[x])) CONTAINS i|i])=0)|x] | MERGE (a:Artist {name:toUpper(trim(e.creatorLabel[y]))}) SET a.dateOfBirth = CASE WHEN NOT trim(e.creatorDOB[y]) = '' THEN trim(e.creatorDOB[y]) ELSE a.dateOfBirth END, a.placeOfBirth = CASE WHEN NOT trim(e.creatorPOB[y]) = '' THEN trim(e.creatorPOB[y]) ELSE a.placeOfBirth END, a.dateOfDeath = CASE WHEN NOT trim(e.creatorDOD[y]) = '' THEN trim(e.creatorDOD[y]) ELSE a.dateOfDeath END, a.placeOfDeath = CASE WHEN NOT trim(e.creatorPOD[y]) = '' THEN trim(e.creatorPOD[y]) ELSE a.placeOfDeath END MERGE (e)-[:CREATOR]->(a) )",
{batchSize:1000, parallel:false}
)//finally map those creators with a wiki entity reference but missing label
CALL apoc.periodic.iterate(
"MATCH (e:Exhibit) WHERE size([z IN e.creatorLabel WHERE NOT size(trim(z))=0]) > 0 RETURN e",
"WITH e FOREACH ( y IN [x IN range(0,size(e.creatorLabel)-1) WHERE size(trim(e.creatorLabel[x])) = 0 AND NOT size(trim(e.creatorWikiData[x])) = 0|x] | MERGE (a:Artist {name:toUpper(trim(e.creatorWikiData[y]))}) SET a.wikiID = trim(e.creatorWikiData[y]), a.dateOfBirth = CASE WHEN NOT trim(e.creatorDOB[y]) = '' THEN trim(e.creatorDOB[y]) ELSE a.dateOfBirth END, a.placeOfBirth = CASE WHEN NOT trim(e.creatorPOB[y]) = '' THEN trim(e.creatorPOB[y]) ELSE a.placeOfBirth END, a.dateOfDeath = CASE WHEN NOT trim(e.creatorDOD[y]) = '' THEN trim(e.creatorDOD[y]) ELSE a.dateOfDeath END, a.placeOfDeath = CASE WHEN NOT trim(e.creatorPOD[y]) = '' THEN trim(e.creatorPOD[y]) ELSE a.placeOfDeath END MERGE (e)-[:CREATOR]->(a) )",
{batchSize:1000, parallel:false}
)//delete incorrect references to countries made from comma separated text mappings earlier
MATCH (a:Artist)
WHERE a.name CONTAINS 'PAYS-BAS'
DETACH DELETE a
…that moment when you think you’re done but you’re not quite - read ‘Artist’ disambiguation (sigh). We’re going to have to fuzzy match and flag what we think we know to be potential duplicates.
MATCH (n:Artist), (m:Artist)
WHERE n.name <> m.name AND apoc.text.clean(n.name) = apoc.text.clean(m.name)
RETURN n.name, n.wikiID, n.dateOfBirth, n.placeOfBirth, n.dateOfDeath, n.placeOfDeath, size(()-[:CREATOR]->(n)) AS worksOfArt
ORDER BY n.name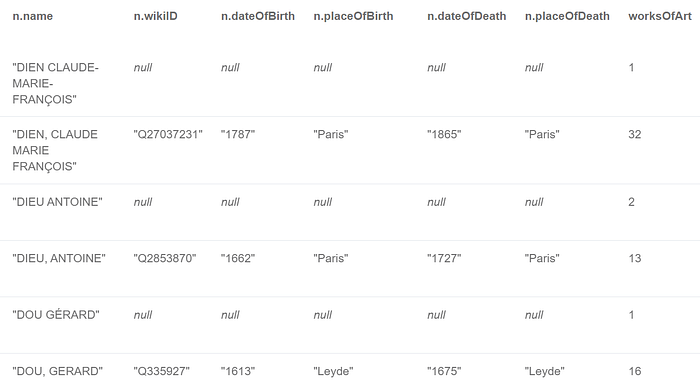
//fuzzy match and associate potential duplicates
MATCH (n:Artist), (m:Artist)
WHERE n.name <> m.name AND apoc.text.clean(n.name) = apoc.text.clean(m.name)
AND ((n.wikiID = m.wikiID) OR (n.wikiID IS NULL AND m.wikiID IS NULL) OR (n.wikiID IS NULL AND m.wikiID IS NOT NULL) OR (n.wikiID IS NOT NULL AND m.wikiID IS NULL))
WITH n, m
ORDER BY n.name
WITH n, COLLECT(m) AS l
FOREACH (x IN l | MERGE (n)-[:ARTIST_FUZZY_MATCH]-(x))//query total works of art by artists with potential duplicates
MATCH p=(:Artist)-[:ARTIST_FUZZY_MATCH*1..]->(:Artist)
WITH p, [x IN NODES(p)][0] AS startNode, [x IN NODES(p)][-1] AS endNode
WHERE NOT EXISTS (()-[:ARTIST_FUZZY_MATCH]->(startNode)) AND NOT EXISTS ((endNode)-[:ARTIST_FUZZY_MATCH]->())
WITH apoc.coll.sort([x IN NODES(p)|x.name]) AS l
WITH l[0] AS artist, apoc.coll.toSet(apoc.coll.flatten(COLLECT(l[1..]))) AS matches
WITH artist, [artist]+matches AS l, matches AS `fuzzy-match`
RETURN artist, toInteger(apoc.coll.sum([x IN l | size(()-[:CREATOR]->(:Artist {name:x}))])) AS worksOfArt, `fuzzy-match`
ORDER BY artist
for example;

Now we could well have decided to merge potential duplicate ‘Artist’ Nodes but I decided to leave them that way, because for one, we’re not quite certain from how they’ve been mapped by the Louvre, and secondly, the whole process of having to combine Node properties on merge and then being able to later query/process them seamlessly, isn’t easy. Also, all the flagging we’ve done is best-case estimation because it clearly hasn’t factored for cases such as this;

or this;

Finally, what sadly remain unmapped are… not the Places that we did successfully eliminate by the way, but People cleverly disguised as such. It would essentially involve combing through the mix to eliminate what’s irrelevant. Since it’s a relatively small number (150+), we choose to move on, assuming we have mapped most of whom were of importance.
//what did not map
MATCH (e:Exhibit) WHERE size([z IN e.creatorLabel
WHERE NOT size(trim(z))=0]) > 0 AND size((e)-[:CREATOR]->()) = 0
UNWIND e.creatorLabel AS i
WITH DISTINCT i
ORDER BY i
RETURN COUNT(i), COLLECT(i)Since the Louvre extract does not speak a lot about the Artists, it’s a good idea to augment what we have, additionally from Wikidata, for cases where we do have the Wikidata entity reference handy. What looks to be of interest to me are the Artist Country of Citizenship, Occupation, Movement, Genre, & Influencers.
CALL apoc.periodic.iterate(
'MATCH (a:Artist)
WHERE a.wikiID IS NOT NULL
RETURN a',
'WITH a,
"SELECT ?item
(GROUP_CONCAT(DISTINCT(?itemCountryLabel); separator = \';\') AS ?country)
(GROUP_CONCAT(DISTINCT(?itemOccupationLabel); separator = \';\') AS ?occupation)
(GROUP_CONCAT(DISTINCT(?itemMovementLabel); separator = \';\') AS ?movement)
(GROUP_CONCAT(DISTINCT(?itemGenreLabel); separator = \';\') AS ?genre)
(GROUP_CONCAT(DISTINCT(?itemStudent); separator = \';\') AS ?student)
(GROUP_CONCAT(DISTINCT(?itemStudentOf); separator = \';\') AS ?studentOf)
WHERE {
VALUES ?item { wd:"+ a.wikiID +" }
OPTIONAL {
?item wdt:P27 ?itemCountry .
?itemCountry rdfs:label ?itemCountryLabel .
FILTER (lang(?itemCountryLabel) = \'en\') .
}
OPTIONAL {
?item wdt:P106 ?itemOccupation .
?itemOccupation rdfs:label ?itemOccupationLabel .
FILTER (lang(?itemOccupationLabel) = \'en\') .
}
OPTIONAL {
?item wdt:P135 ?itemMovement .
?itemMovement rdfs:label ?itemMovementLabel .
FILTER (lang(?itemMovementLabel) = \'en\') .
}
OPTIONAL {
?item wdt:P136 ?itemGenre .
?itemGenre rdfs:label ?itemGenreLabel .
FILTER (lang(?itemGenreLabel) = \'en\') .
}
OPTIONAL {
?item wdt:P802 ?itemStudent .
}
OPTIONAL {
?item wdt:P1066 ?itemStudentOf .
}
} GROUP BY ?item" AS query
CALL apoc.load.jsonParams("http://query.wikidata.org/sparql?format=json&query=" + apoc.text.urlencode(query), {}, null)
YIELD value
WITH a, value.results.bindings AS artists
UNWIND artists AS artist
WITH a, artist.country.value AS country,
artist.occupation.value AS occupation,
artist.movement.value AS movement,
artist.genre.value AS genre,
artist.student.value AS student,
artist.studentOf.value AS studentOf
SET
a.wikiCountryCitizenship = CASE WHEN NOT country = \'\' THEN country ELSE NULL END,
a.wikiOccupation = CASE WHEN NOT occupation = \'\' THEN occupation ELSE NULL END,
a.wikiMovement = CASE WHEN NOT movement = \'\' THEN movement ELSE NULL END,
a.wikiGenre = CASE WHEN NOT genre = \'\' THEN genre ELSE NULL END,
a.wikiStudent = CASE WHEN NOT student = \'\' THEN student ELSE NULL END,
a.wikiStudentOf = CASE WHEN NOT studentOf = \'\' THEN studentOf ELSE NULL END',
{batchSize:10, parallel:true}
)Now, I encountered a HTTP 429 error which has to do with reading too many requests in a time frame. We’ll need to further ration our requests, if so.
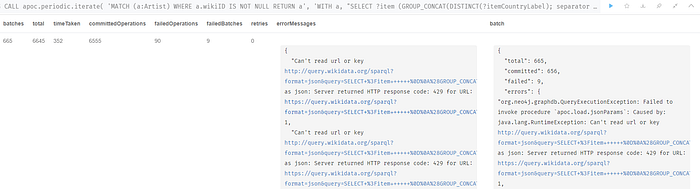
MATCH (a:Artist)
WHERE a.wikiID IS NOT NULL
FOREACH ( x IN CASE WHEN a.wikiOccupation IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN SPLIT(a.wikiOccupation,';') | MERGE (o:Occupation {occupation:toUpper(trim(y))}) MERGE (a)-[:OCCUPATION]->(o) ) )
FOREACH ( x IN CASE WHEN a.wikiMovement IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN SPLIT(a.wikiMovement,';') | MERGE (m:Movement {movement:toUpper(trim(y))}) MERGE (a)-[:MOVEMENT]->(m) ) )
FOREACH ( x IN CASE WHEN a.wikiGenre IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN SPLIT(a.wikiGenre,';') | MERGE (g:Genre {genre:toUpper(trim(y))}) MERGE (a)-[:GENRE]->(g) ) )MATCH (a:Artist)
WHERE a.wikiID IS NOT NULL AND a.wikiCountryCitizenship IS NOT NULL
WITH a, SPLIT(a.wikiCountryCitizenship,';') AS countries
UNWIND countries AS country
MATCH (c:Country)
WHERE toUpper(trim(c.countryEN)) = toUpper(trim(country))
MERGE (a)-[:COUNTRY]->(c)MATCH (a:Artist)
WHERE a.wikiID IS NOT NULL AND a.wikiStudent IS NOT NULL
WITH a, [x IN SPLIT(a.wikiStudent,';')|SPLIT(x,'/')[-1]] AS students
UNWIND students AS student
MATCH (s:Artist {wikiID:toUpper(trim(student))})
MERGE (s)-[:TEACHER]->(a)MATCH (a:Artist)
WHERE a.wikiID IS NOT NULL AND a.wikiStudentOf IS NOT NULL
WITH a, [x IN SPLIT(a.wikiStudentOf,';')|SPLIT(x,'/')[-1]] AS teachers
UNWIND teachers AS teacher
MATCH (t:Artist {wikiID:toUpper(trim(teacher))})
MERGE (a)-[:TEACHER]->(t)
Looking closely at the ‘Features’ data from the Louvre json extract and the ‘Depictions’ data from Wikidata (that we did additionally enrich the ‘Exhibit’ Nodes with), I reckon they could mean the same thing. Same observation goes for ‘Period’ from the Louvre json extract and ‘Movement’ data from Wikidata. It probably is worthwhile filling missing data from trusted external sources when your only supposedly single source of truth does not provide for it. In our case, Wikidata is seen to have the ‘Movement’ documented, where ‘Period’ is seen to be missing for an Exhibit.
MATCH (n:Exhibit)
WHERE n.wikiMovement IS NOT NULL AND n.period IS NULL
RETURN COUNT(n)Now since the ‘Movement’ Node data is in language English and their French translations are not seen to exactly coincide with the ‘Period’ data in language French, we could map the French translations along with their aliases from Wikidata to the ‘Period’ Node data using a fuzzy match, wherever possible.
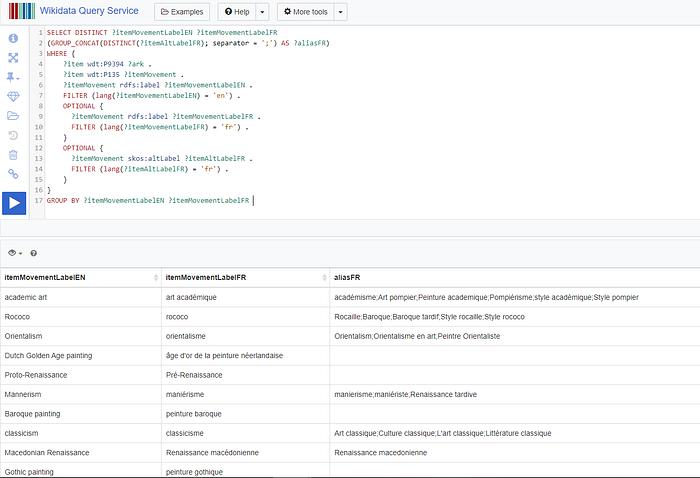
//fetch the translations for movements
CALL apoc.periodic.iterate(
'WITH
"SELECT DISTINCT ?itemMovementLabelEN ?itemMovementLabelFR
(GROUP_CONCAT(DISTINCT(?itemAltLabelFR); separator = \';\') AS ?aliasFR)
WHERE {
?item wdt:P9394 ?ark .
?item wdt:P135 ?itemMovement .
?itemMovement rdfs:label ?itemMovementLabelEN .
FILTER (lang(?itemMovementLabelEN) = \'en\') .
OPTIONAL {
?itemMovement rdfs:label ?itemMovementLabelFR .
FILTER (lang(?itemMovementLabelFR) = \'fr\') .
}
OPTIONAL {
?itemMovement skos:altLabel ?itemAltLabelFR .
FILTER (lang(?itemAltLabelFR) = \'fr\') .
}
}
GROUP BY ?itemMovementLabelEN ?itemMovementLabelFR" AS query
CALL apoc.load.jsonParams("http://query.wikidata.org/sparql?format=json&query=" + apoc.text.urlencode(query), {}, null)
YIELD value
RETURN value',
'WITH value.results.bindings AS movements
UNWIND movements AS movement
WITH toUpper(trim(movement.itemMovementLabelEN.value)) AS movementEN, toUpper(trim(movement.itemMovementLabelFR.value)) AS movementFR, toUpper(trim(movement.aliasFR.value)) AS aliasFR
MATCH (m:Movement {movement:movementEN})
SET m.movementFR = movementFR,
m.aliasFR = CASE WHEN NOT aliasFR = \'\' THEN aliasFR ELSE NULL end',
{batchSize:10, parallel:true}
)//fuzzy match movements with periods
MATCH (p:Period)
WITH p
MATCH (m:Movement)
WITH p, m, [m.movementFR]+SPLIT(m.aliasFR,';') AS l
WITH p, m, [x IN l WHERE (apoc.text.levenshteinSimilarity(x, p.period) + apoc.text.sorensenDiceSimilarity(x, p.period))/2 > 0.6|x] AS i
WHERE size(i) > 0
RETURN p.period AS period, apoc.coll.flatten(COLLECT([m.movementFR]+SPLIT(m.aliasFR,';'))) AS movements

Well, for a few exceptions (that we could manually clean up later), that does look satisfactory for now, so we can go ahead and link the two.
MATCH (p:Period)
WITH p
MATCH (m:Movement)
WITH p, m, [m.movementFR]+SPLIT(m.aliasFR,';') AS l
WITH p, m, [x IN l WHERE (apoc.text.levenshteinSimilarity(x, p.period) + apoc.text.sorensenDiceSimilarity(x, p.period))/2 > 0.6|x] AS i
WHERE size(i) > 0
MERGE (m)-[:FUZZY_MATCH]->(p)Next we look at similarity between ‘Features’ in the json extract and ‘Depictions’ as externally enriched from Wikidata. We do have cases where an Exhibit is missing with ‘Features’ from the json extract but does have documented ‘Depictions’ in Wikidata.
MATCH (n:Exhibit)
WHERE n.wikiDepiction IS NOT NULL AND n.feature IS NULL
RETURN COUNT(n)Assuming them to be the same, we add ‘Depictions’ to the ‘Features’ corpus and re-map Exhibits to ‘Features’ to see how many additional missing references we can account for.
//fetch the translation for depictions
CALL apoc.periodic.iterate(
'WITH
"SELECT ?ark
(GROUP_CONCAT(DISTINCT(?itemDepictLabel); separator = \';\') AS ?depiction)
WHERE {
?item wdt:P9394 ?ark .
?item wdt:P180 ?itemDepict .
?itemDepict rdfs:label ?itemDepictLabel .
FILTER (lang(?itemDepictLabel) = \'fr\') .
}
GROUP BY ?ark" AS query
CALL apoc.load.jsonParams("http://query.wikidata.org/sparql?format=json&query=" + apoc.text.urlencode(query), {}, null)
YIELD value
RETURN value',
'WITH value.results.bindings AS arks
UNWIND arks AS ark
WITH \'cl\'+ark.ark.value AS ark, ark.depiction.value AS depiction
MATCH (e:Exhibit {arkID:ark})
SET e.wikiDepictionFR = depiction',
{batchSize:100, parallel:true}
)//map the missing features to exhibits
CALL apoc.periodic.iterate(
"MATCH (e:Exhibit)
RETURN e",
"
WITH e
FOREACH ( x IN CASE WHEN e.wikiDepictionFR IS NOT NULL THEN [1] ELSE [] END | FOREACH ( y IN SPLIT(e.wikiDepictionFR,';') | MERGE (fe:Feature {feature:toUpper(trim(y))}) MERGE (e)-[:FEATURE]->(fe) ) )
",
{batchSize:1000, parallel:false}
)
Moving on, if you didn’t already know, the Louvre is not just in France but around the world! In France, there’s the ‘National Museum of Eugene Delacroix’, the ‘Louvre Lens’ and the ‘Louvre Conservation Center’ that are physical extensions of the Louvre, while the ‘Louvre Abu Dhabi’ is the result of an unprecedented partnership between France and the United Arab Emirates, and France’s largest cultural project abroad.

What that means is that we got to inspect our Location mapping to see if it all adds up. It doesn’t, by the way (so much for organization skills and free lunches). So there’s work to do.
-- update louvre lens' locations to "LOUVRE-LENS"
MATCH (lens:Location {location:'LOUVRE-LENS'})
MATCH (e:Exhibit)-[r:LOCATION]->(l:Location)
WHERE l <> lens AND l.location CONTAINS 'LOUVRE-LENS'
WITH e, r, lens
MERGE (e)-[:LOCATION]->(lens)
DELETE rMATCH (l:Location)
WHERE l.location CONTAINS 'LOUVRE-LENS' AND NOT l.location = 'LOUVRE-LENS'
DELETE lMATCH (e:Exhibit)-[:LOCATION]->(l:Location)
WHERE l.location CONTAINS 'LOUVRE-LENS'
RETURN l.location, COUNT(e)-- update delacroix locations to "MUSÉE NATIONAL EUGÈNE DELACROIX"
MATCH (d:Location {location:'MUSÉE NATIONAL EUGÈNE DELACROIX'})
MATCH (e:Exhibit)-[r:LOCATION]->(l:Location)
WHERE l <> d AND l.location CONTAINS 'DELACROIX'
WITH e, r, d
MERGE (e)-[:LOCATION]->(d)
DELETE rMATCH (l:Location)
WHERE l.location CONTAINS 'DELACROIX' AND NOT l.location = 'MUSÉE NATIONAL EUGÈNE DELACROIX'
DELETE lMATCH (e:Exhibit)-[:LOCATION]->(l:Location)
WHERE l.location CONTAINS 'DELACROIX'
RETURN l.location, COUNT(e)
So, this is what the marked inventory looks like. Now these don’t add up to what the above site projections are, possibly because the ‘Current Location’ for more than 1,80,000 works of art have been classified as ‘not exposed’. We could further resort to the ‘Holding’ & ‘Leasing’ Authority of an Exhibit and yet, not be certain of its ‘Current Location’. So we leave it at that.

MATCH (e:Exhibit)-[:LOCATION]->(l:Location)
WHERE NOT l.location CONTAINS 'LOUVRE' AND NOT l.location CONTAINS 'DELACROIX'
RETURN l.location, COUNT(e)MATCH (e:Exhibit)-[:LOCATION]->(l:Location {location:'NON EXPOSÉ'})
MATCH (e)-[r]->(a:Authority)
WHERE a.authority CONTAINS 'LOUVRE' OR a.authority CONTAINS 'DELACROIX'
RETURN a.authority AS authority, TYPE(r) AS type, COUNT(e) AS cnt
ORDER BY cnt DESC, authority
Finally, we label each Exhibit by its category as depicted on the Louvre Collections site. Since there is no parent category tagging in the json extract, the only way to do this is to download the csv extracts filtered by ‘Category’, from the Louvre Collections page, which essentially contain the ark ID among the title, artist, timeline and collection details. By matching on the ark ID, we can label the ‘Exhibit’ Nodes to tally with the ‘Category’ numbers on the Louvre Collections page. I won’t be running through this exercise to save us time and torture. Other things to do would be to inspect ‘Place’ from the Exhibit Place of Creation & Discovery / Artist Place of Birth & Death, circle back and map unmapped Artists to their works of creation and delete irrelevant Period to Movement references.
Alright! With that, we’ve pretty much accounted for the data we’ve been looking to connect. Or atleast, we’ve tried to.
Takeaways? here are mine;
- real world data is seldom in a form that’s ready for consumption, be prepared to invest time early on in data curation
- the accuracy of your analysis is only as good as your data
- plug missing references/data using trusted external sources such as Wikidata; if it’s good enough for Google, it’s good enough for you
- Neo4j can handle data transformation with inbuilt and extended library support; do leverage at will (the APOC library in use here must be a tool within your Neo4j toolbox)
What now? If you’ve come this far (and that is the whole nine yards for a Part 1 series), stay tuned for what I plan to do with the graphed Louvre Collection!

References:
https://schema.org/VisualArtwork
https://www.w3.org/TR/rdf-schema/
https://www.wikidata.org/wiki/Wikidata:Relation_between_properties_in_RDF_and_in_Wikidata
https://www.wikidata.org/wiki/Wikidata:SPARQL_query_service/query_optimization
https://www.wikidata.org/wiki/Wikidata:SPARQL_query_service/suggestions#Performance_surprises
https://www.wikidata.org/wiki/Wikidata:SPARQL_query_service/queries/examples

